Scenario
Suppose you have a Ruby on Rails app, where users write and post articles. You want to enable the users to ask questions about all the articles in the database, get a response, and links to the most relevant articles.
Why not use Postgres full text search? Well, asking and answering questions is not the same as searching for keywords. Also, as good as full text search is, it is not as good as AI at understanding the meaning of the text. For example:
If a user asks:
Are humans great?
And the database contains articles that mention:
People are awesome
Then full text search fails to find the article, because it does not understand that “humans” and “people” are the same thing. The only word they have in common is “are”, and that’s not enough to make a good match.
Tools
- Ruby on Rails, it does not matter if it is an api only or a full stack app.
- Postgres
- Postgres pgvector extension
- OpenAI API key (or any other AI model that’s capable of generating embeddings)
The Plan
- Create a migration that enables the pgvector extension in your database.
- Create a model to store the embeddings of your data, that belongs to a polymorphic
embeddablemodel. - Create a service object that will communicate with the OpenAI embeddings API, which will receive a text and return an embedding.
- Create an
Embeddablemodel concern that will include the logic to generate the embeddings and store them in the database. - Create a controller that will receive the user’s query, generate an embedding, and query the database for the most similar embeddings.
Sounds simple, right?
If you are not familiar with the term embeddings, it may seem like some magic is going on, but in reality, there’s none.
Embeddings
Given OpenAI’s own definition:
OpenAI’s text embeddings measure the relatedness of text strings
Okay, that really explains what it does, but how does it even look like? How can we use it?
An embedding is nothing more than a vector of floating point numbers that represents how a text scores (field) in different aspects (dimensions)
Example
Given a method that given a text, it generates an embedding of 2 dimensions, where the first dimension represents how positive the text is, and the second dimension represents how much the text talks about cats.
# @param input [String]
# @return [Array<Float>]
def create_embedding(input)
if input.match?(/(like|love)/)
positive = 1.0
else
positive = 0.0
end
if input.match?(/(cats|cat|feline|furball)/)
cats = 1.0
else
cats = 0.0
end
[positive, cats]
end
create_embedding("I like cats") # => [1.0, 1.0]
In this example, the string "I like cats" is transformed into a vector of 2 dimensions.
If we were to create an embedding for the string "I like dogs", we would get a different vector
create_embedding("I like dogs") # => [1.0, 0.0]
And if we were to create an embedding for a string with a very different meaning, we would get a very different vector
create_embedding("Mondays suck") # => [0.0, 0.0]
This is a very simple algorithm for creating embeddings that does not really use trained LLM’s, but it serves as a good example of what embeddings are and how they are generated.
Calculating the similarity between embeddings
Now that we know how embeddings are generated, we can calculate the similarity between them.
require 'bundler/inline'
gemfile do
source 'https://rubygems.org'
gem 'matplotlib', '~> 1.3.0'
end
require 'matplotlib/pyplot'
plt = Matplotlib::Pyplot
cats = [0.238, 0.839]
dogs = [0.248, 0.859]
mondays = [0.938, 0.239]
# scatter plot
plt.scatter(*cats, color: 'r')
plt.scatter(*dogs, color: 'g')
plt.scatter(*mondays, color: 'b')
plt.legend(['cats', 'dogs', 'mondays'])
plt.show()
This will generate a plot that looks like this:
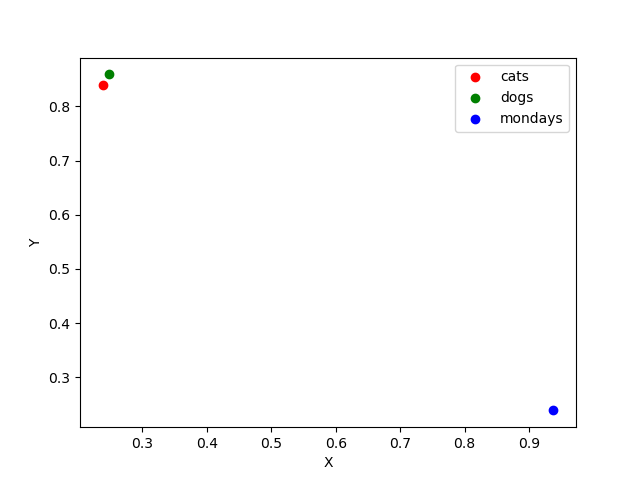
We can now see that the vectors for "I like cats" and "I like dogs" are very close to each other, while the vector for "Mondays suck" is very far from the other two.
Calculating the similarity between embeddings
The way we can check if two embeddings are similar is by calculating the similarity between them. For doing this, we’ll use one of 2 methods: cosine similarity or euclidean distance.
Cosine similarity
Given Wikipedia’s definition:
[…] cosine similarity is a measure of similarity between two non-zero vectors defined in an inner product space. […]
The cosine similarity between any two vectors is calculated as follows:
\[\text{cosine_similarity} = \frac{A \cdot B}{\|A\| \times \|B\|}\]Where:
- A and B are the non-zero vectors
The cosine_similarity method in Ruby could look like this:
# @param a [Array<Float>]
# @param b [Array<Float>]
# @return [Float]
def cosine_similarity(a, b)
dot_product = a.zip(b).sum { |x, y| x * y }
magnitude_a = Math.sqrt(a.sum { |x| x**2 })
magnitude_b = Math.sqrt(b.sum { |x| x**2 })
dot_product / (magnitude_a * magnitude_b)
end
If we run this method with the vectors we created before, we would get the following results:
cosine_similarity(cats, dogs) # => 0.9999891633941651
cosine_similarity(cats, mondays) # => 0.5019901922103566
cosine_similarity(dogs, mondays) # => 0.5060111156140782
As we can see, the cosine similarity between the vectors for "I like cats" and "I like dogs" is very close to 1, while the cosine similarity between the vectors for "I like cats" and "Mondays suck" is around 0.5
Euclidean distance
Given Wikipedia’s definition:
In mathematics, the Euclidean distance between two points in Euclidean space is the length of the line segment between them. […]
The euclidean distance between any two vectors is calculated as follows:
\[\text{euclidean_distance} = \sqrt{\sum_{i=1}^{n} (A_i - B_i)^2}\]Where:
- A and B are the non-zero vectors
The euclidean_distance method in Ruby could look like this:
# @param a [Array<Float>]
# @param b [Array<Float>]
# @return [Float]
def euclidean_distance(a, b)
Math.sqrt(a.zip(b).sum { |x, y| (x - y)**2 })
end
If we run this method with the vectors we created before, we would get the following results:
euclidean_distance(cats, dogs) # => 0.022360679774997918
euclidean_distance(cats, mondays) # => 0.9219544457292886
euclidean_distance(dogs, mondays) # => 0.9276313923105448
As we can see, the euclidean distance between the vectors for "I like cats" and "I like dogs" is very close to 0, while the euclidean distance between the vectors for "I like cats" and "Mondays suck" is around 1
This means, that the vectors for "I like cats" and "I like dogs" are very close to each other, while the vector for "Mondays suck" is very far from the other two.
OpenAi embeddings
OpenAI’s embeddings are a bit more complex than the simple example we’ve seen before, but the idea remains the same.
OpenAI’s embeddings generated by the text-embedding-ada-002 model are 1536 dimensions long, and they are generated using a model that has been trained on a large dataset of text.
Each dimension in the vector represents a different aspect of the text, and the value of the dimension represents the importance of that aspect in the text.
However, the way we use the embeddings is the same as before, we will be sending a text to the OpenAI API, and it will return a 1536 dimensions long vector. After that, we can calculate the similarity between the vectors using the cosine similarity or the euclidean distance by using Postgres pgvector extension’s methods.
Show me the code
Now that we have a basic understanding of what embeddings are and how to calculate the similarity between them, let’s move on to the implementation.
Step 1: Install neighbor gem
The neighbor gem provides the rails tooling we need to query the database for the most similar vectors:
- pgvector support
- ActiveRecord integration
- ActiveRecord scopes for nearest neighbor search using cosine similarity or euclidean distance
# Gemfile
gem 'neighbor'
Then run:
rails generate neighbor:vector
rails db:migrate
Step 2: Create a model to store the embeddings
# db/migrate/20240321120000_create_embeddings.rb
class CreateEmbeddings < ActiveRecord::Migration[6.1]
def change
create_table :embeddings do |t|
t.references :embeddable, polymorphic: true, null: false
t.vector, :vector, limit: 1536, null: false
end
end
end
class Embedding < ApplicationRecord
belongs_to :embeddable, polymorphic: true
validates :vector, presence: true
end
Step 3: Create a service object to communicate with the OpenAI embeddings API
# app/services/open_ai/embeddings.rb
require 'net/http'
class OpenAi::Embeddings
def initialize(api_key)
@api_key = api_key
end
def self.call(text)
new(ENV["OPENAI_API_KEY"]).call(text)
end
def call(text)
response = Net::HTTP.post(
URI("https://api.openai.com/v1/embeddings"),
{
input: text,
model: "text-embedding-ada-002"
}.to_json,
"Authorization" => "Bearer #{@api_key}",
"Content-Type" => "application/json"
)
JSON.parse(response.body)["data"].first["embedding"]
end
end
Step 4: Create an Embeddable model concern
# app/models/concerns/embeddable.rb
# Usage:
# class Article < ApplicationRecord
# include Embeddable
# embedding_for :content
#
# def text
# content
# end
# end
module Embeddable
extend ActiveSupport::Concern
included do
has_one :embedding, as: :embeddable, dependent: :destroy
after_create_commit :create_embedding
end
class_methods do
def embedding_for(column = :text, generator: "OpenAi::Embeddings")
@embedding_column = column
@embedding_generator = klass
end
def embedding_generator
@embedding_generator
end
def embedding_column
@embedding_column
end
end
def create_embedding
embedding = Embedding.create(
embeddable: self,
vector: embedding_generator.call(embedding_text)
)
end
def embedding_text
send(embedding_column)
end
private
def embedding_generator
self.class.embedding_generator.constantize.new
end
end
Step 5: Create a controller that will receive the user’s query
# app/controllers/search_controller.rb
class SearchController < ApplicationController
def index
query = params[:query]
embedding = OpenAi::Embeddings.call(query)
embeddings = Embedding.nearest_neighbor(:vector, embedding, distance: 'cosine').limit(embeddings_limit)
@results = embeddings.map(&:embeddable)
respond_to do |format|
format.json { render json: @results.to_json }
format.html
end
end
private
def embeddings_limit
@embeddings_limit ||= begin
unconstrained_limit = params[:limit] || 10
[unconstrained_limit.to_i, 10].min
end
end
end
Taking it further
You may want to take this a step further, and create a context from the most similar embeddings, and then use the context to generate a response to the user’s query. To achieve this, you could use the OpenAI GPT 3.5 Turbo model.
# app/services/open_ai/completions.rb
require 'net/http'
class OpenAi::Completions
def initialize(api_key)
@api_key = api_key
end
def self.call(prompt, context: '')
new(ENV["OPENAI_API_KEY"]).call(prompt, context: context)
end
def call(prompt, **kwargs)
messages = [{ role: 'user', content: prompt }]
kwargs.each do |role, content|
messages << { role:, content:}
end
response = Net::HTTP.post(
URI("https://api.openai.com/v1/chat/completions"),
{
model: "gpt-3.5-turbo",
messages:
}.to_json,
"Authorization "=> "Bearer #{@api_key}",
"Content-Type" => "application/json"
)
JSON.parse(response.body)["choices"].first["message"]["content"]
end
end
# app/controllers/search_controller.rb
class SearchController < ApplicationController
def index
# get the user's query
query = params[:query]
# get the embedding for the user's query
embedding = OpenAi::Embeddings.get(query)
# get the most similar embeddings from the database
embeddings = Embedding.nearest_neighbor(:vector, embedding, distance: 'cosine').limit(embeddings_limit)
# get the results models from the most similar embeddings
@results = embeddings.map(&:embeddable)
# Generate context from the most similar embeddings
context = generate_context(@results)
# Ask OpenAI for a completion
@response = OpenAi::Completions.call(query, system: context)
respond_to do |format|
# json response includes the results and the response
format.json { render json: { results: @results.to_json, response: @response } }
format.html
end
end
private
def generate_context(results)
results.map(&:embedding_text).join(' ')
end
end
Conclusion
By leveraging Postgres and the pgvector extension alongside OpenAI’s API, we’ve established a robust system for querying and analyzing user-generated content within our database in a way that’s both efficient and developer friendly.
You now have the tools needed to integrate an AI search feature in your Rails app, that leverages the data that is already in your database.